In search mode, firstly the bottom-up saliency map is computed.
Additionally, we determine a top-down saliency map that
competes with the bottom-up map for saliency. The
top-down map is composed of an excitation and an inhibition map.
The excitation map ![]() is the weighted sum of all feature maps that are
important for the learned object, namely the features with weights
greater than 1. The inhibition map
is the weighted sum of all feature maps that are
important for the learned object, namely the features with weights
greater than 1. The inhibition map ![]() contains the feature maps that are
not present in the learned object, namely the features with weights
smaller than 1:
contains the feature maps that are
not present in the learned object, namely the features with weights
smaller than 1:
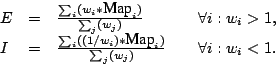
The top-down saliency map ![]() is obtained by:
is obtained by:
![]() .
The final saliency map
.
The final saliency map ![]() is composed as a combination of bottom-up and
top-down influences.
When fusing the maps, it is possible to determine the degree to which each
map contributes by weighting the maps with a
top-down factor
is composed as a combination of bottom-up and
top-down influences.
When fusing the maps, it is possible to determine the degree to which each
map contributes by weighting the maps with a
top-down factor
![]() :
:
![]() .
.
With ![]() , VOCUS looks only for the specified target. With
, VOCUS looks only for the specified target. With
![]() , also bottom-up cues have an influence and may divert the
focus of attention. This is also an important mechanism in human
visual attention. E.g., a person suddenly entering a room
catches immediately our attention, independently of the task. For
the application discussed in this paper, we always use
, also bottom-up cues have an influence and may divert the
focus of attention. This is also an important mechanism in human
visual attention. E.g., a person suddenly entering a room
catches immediately our attention, independently of the task. For
the application discussed in this paper, we always use ![]() and use the bottom-up saliency only to learn the weights of the
training objects. Thus, the robot focuses its attention completely
on the ball and not to play foul on other robots.
and use the bottom-up saliency only to learn the weights of the
training objects. Thus, the robot focuses its attention completely
on the ball and not to play foul on other robots.